Частота писем - Letter frequency
| Письмо | Относительная частота на английском языке | |||
|---|---|---|---|---|
| Тексты | Словари | |||
| а | 8.2% | 7.8% | ||
| б | 1.5% | 2% | ||
| c | 2.8% | 4% | ||
| d | 4.3% | 3.8% | ||
| е | 13% | 11% | ||
| ж | 2.2% | 1.4% | ||
| грамм | 2% | 3% | ||
| час | 6.1% | 2.3% | ||
| я | 7% | 8.6% | ||
| j | 0.15% | 0.21% | ||
| k | 0.77% | 0.97% | ||
| л | 4% | 5.3% | ||
| м | 2.4% | 2.7% | ||
| п | 6.7% | 7.2% | ||
| о | 7.5% | 6.1% | ||
| п | 1.9% | 2.8% | ||
| q | 0.095% | 0.19% | ||
| р | 6% | 7.3% | ||
| s | 6.3% | 8.7% | ||
| т | 9.1% | 6.7% | ||
| ты | 2.8% | 3.3% | ||
| v | 0.98% | 1% | ||
| ш | 2.4% | 0.91% | ||
| Икс | 0.15% | 0.27% | ||
| у | 2% | 1.6% | ||
| z | 0.074% | 0.44% | ||
Частота писем просто количество раз, когда буквы алфавита появляются в среднем в письменном языке. Анализ частоты букв восходит к арабскому математику. Аль-Кинди (ок. 801–873 нашей эры), который формально разработал метод взлома шифров. Анализ частоты писем приобрел важность в Европе с развитием подвижный тип в 1450 году нашей эры, где нужно оценить количество шрифтов, необходимых для каждой формы буквы. Лингвисты используют частотный анализ букв как элементарный метод для идентификация языка, где он особенно эффективен для определения того, является ли неизвестная система письма алфавитной, слоговой или идеографической.
Использование буквенных частот и частотный анализ играет фундаментальную роль в криптограммы и несколько словесных головоломок, в том числе Палач, Скрэббл и телешоу игры Колесо фортуны. Одно из самых ранних описаний в классической литературе применения знания частоты английских букв для решения криптограммы находится в Эдгар Аллан По известная история Золотой жук, где метод успешно применяется для расшифровки сообщения с инструкцией о местонахождении сокровища, спрятанного Капитан Кидд.[1]
Частота букв также сильно влияет на дизайн некоторых раскладки клавиатуры. Самые частые буквы находятся в нижнем ряду Пишущая машинка Blickensderfer, а домашний ряд из Раскладка клавиатуры Дворжака.
Фон
Частота появления букв в тексте была изучена для использования в криптоанализ, и частотный анализ в частности, еще со времен иракского математика Аль-Кинди (ок. 801–873 гг. н. э.), которые формально разработали метод (шифры, которые можно взломать с помощью этой техники, восходят, по крайней мере, к Шифр цезаря изобретен Юлий Цезарь, так что этот метод можно было использовать в классические времена). Анализ частоты писем приобрел дополнительное значение в Европе с развитием подвижный тип в 1450 году нашей эры, где нужно оценить количество шрифтов, необходимых для каждой формы письма, о чем свидетельствуют различия в размере отделения для писем в типографских случаях.
В основе данного языка нет точного частотного распределения букв, поскольку все авторы пишут немного по-разному. Однако большинство языков имеют характерное распределение, которое явно проявляется в более длинных текстах. Даже столь резкие языковые изменения, как переход от старого английского к современному (считающемуся взаимно непонятным), демонстрируют сильные тенденции в частотности соответствующих букв: по небольшой выборке библейских отрывков от наиболее частых к наименее частым, enaid sorhm tgþlwu æcfy ðbpxz старого английского сравнивается с eotha sinrd luymw fgcbp kvjqxz современного английского языка, с самыми резкими различиями в формах букв.[2]
Линотипные машины для английского языка предполагается, что порядок букв, от наиболее распространенного до наименее распространенного, является Этаоин Шрдлу cmfwyp vbgkjq xz на основе опыта и обычаев ручных наборщиков. Эквивалент французского языка был elaoin sdrétu cmfhyp vbgwqj xz.
Распределение алфавита по азбуке Морзе на группы букв, требующих равного количества времени для передачи, а затем сортировка этих групп в порядке возрастания, дает e it san hurdm wgvlfbk opxcz jyq.[а] Частота букв использовалась другими телеграфными системами, такими как Код Мюррея.
Подобные идеи используются в современных Сжатие данных такие методы, как Кодирование Хаффмана.
Частоты букв, например частота слов, как правило, варьируются в зависимости от автора и темы. Нельзя написать эссе о рентгеновских лучах без частого использования крестиков, и эссе будет иметь своеобразную частоту букв, если эссе посвящено использованию рентгеновских лучей для лечения зебр в Катаре. У разных авторов есть привычки, которые могут быть отражены в использовании букв. Хемингуэй стиль письма, например, заметно отличается от Фолкнер с. Письмо, биграмма, триграмма, частота слов, длина слова и длина предложения могут быть рассчитаны для конкретных авторов и использованы для доказательства или опровержения авторства текстов, даже для авторов, стили которых не столь расходятся.
Точную среднюю частоту букв можно определить только путем анализа большого количества репрезентативного текста. Благодаря наличию современных вычислений и коллекций больших текстовые корпуса, такие расчеты производятся легко. Примеры могут быть взяты из различных источников (репортажи в прессе, религиозные тексты, научные тексты и художественная литература общего характера), и существуют различия, особенно для художественной литературы общего характера, с положением «h» и «i», причем «h» становится все более распространенным.
Герберт С. Зим в своем классическом вводном тексте по криптографии «Коды и секретное письмо» дает последовательность английских букв как «ETAON RISHD LFCMU GYPWB VKJXZQ», наиболее распространенные пары букв как «TH HE AN RE ER IN ON AT ND ST ES EN OF TE». ED OR TI HI AS TO », а наиболее распространенные удвоенные буквы -« LL EE SS OO TT FF RR NN PP CC ».[3]
Также обратите внимание, что разные диалекты языка также влияют на частоту букв. Например, автор в США создаст текст, в котором буква «z» встречается чаще, чем автор в Соединенном Королевстве, пишущий на ту же тему: такие слова, как «анализировать», «извиняться» и «признавать» содержат письмо в американском английском, тогда как те же слова пишутся «анализировать», «извиняться» и «признавать» в британском английском. Это сильно повлияет на частоту буквы «z», поскольку это редко используемая буква британцами в английском языке.[4]
«Двенадцать первых» букв составляют около 80% от общего использования. «Восьмерка» букв составляет около 65% от общего использования. Частота букв как функция ранга может быть хорошо описана несколькими функциями ранга с двухпараметрическим Функция ранга Cocho / Beta быть лучшим.[5] Другая функция ранжирования без регулируемого свободного параметра также достаточно хорошо соответствует частотному распределению букв.[6] (та же функция была использована для подбора частоты аминокислот в белковых последовательностях.[7]) Шпион, использующий Шифр VIC или какой-либо другой шифр, основанный на двойной шахматной доске, обычно использует мнемонику, такую как «грех ошибиться» (отбрасывание второго «r»)[8][9] или "в один прекрасный день, сэр"[10] чтобы запомнить восемь верхних символов.
Относительные частоты букв в английском языке

Есть три способа подсчета количества букв, которые приводят к очень разным диаграммам для общих букв. Первый метод, используемый в таблице ниже, - это подсчет частоты букв в корневых словах словаря. Во-вторых, при подсчете учитываются все варианты слова, такие как «рефераты», «абстракции» и «абстрагирование», а не только корень слова «абстрактное». Эта система приводит к тому, что буквы вроде 's' появляются гораздо чаще, например, при подсчете букв из списков наиболее часто используемых английских слов в Интернете. Последний вариант - подсчет букв в зависимости от частоты их использования в реальных текстах, в результате чего определенные буквенные комбинации, такие как 'th', становятся более распространенными из-за частого использования общих слов, таких как "the", "then", "both", и т. д. Подобные измерения абсолютной частоты использования используются при создании раскладок клавиатуры или частот букв в старых печатных машинах.
Анализ статей в Кратком Оксфордском словаре без учета частоты использования слов дает порядок «EARIOTNSLCUDPMHGBFYWKVXZJQ».[11]
Приведенная ниже таблица частотности писем взята с веб-сайта Павла Мички, который цитирует Роберта Леванда. Криптологическая математика.[12]
По словам Леванда, буквы расположены в порядке от наиболее распространенного до наименее распространенного: etaoinshrdlcumwfgypbvkjxqz. Порядок действий Леванда немного отличается от других, таких как проект Math Explorer Корнельского университета, который создал таблицу после измерения 40 000 слов.[13]
В английском языке пробел немного чаще, чем верхняя буква (e)[14] а неалфавитные символы (цифры, знаки препинания и т. д.) вместе занимают четвертую позицию (уже включив пробел) между т и а.[15]
Относительные частоты первых букв слова в английском языке
| Письмо | Относительная частота как первая буква английского слова | |||
|---|---|---|---|---|
| Тексты | Словари | |||
| а | 1.7% | 5.7% | ||
| б | 4.4% | 6% | ||
| c | 5.2% | 9.4% | ||
| d | 3.2% | 6.1% | ||
| е | 2.8% | 3.9% | ||
| ж | 4% | 4.1% | ||
| грамм | 1.6% | 3.3% | ||
| час | 4.2% | 3.7% | ||
| я | 7.3% | 3.9% | ||
| j | 0.51% | 1.1% | ||
| k | 0.86% | 1% | ||
| л | 2.4% | 3.1% | ||
| м | 3.8% | 5.6% | ||
| п | 2.3% | 2.2% | ||
| о | 7.6% | 2.5% | ||
| п | 4.3% | 7.7% | ||
| q | 0.22% | 0.49% | ||
| р | 2.8% | 6% | ||
| s | 6.7% | 11% | ||
| т | 16% | 5% | ||
| ты | 1.2% | 2.9% | ||
| v | 0.82% | 1.5% | ||
| ш | 5.5% | 2.7% | ||
| Икс | 0.045% | 0.05% | ||
| у | 0.76% | 0.36% | ||
| z | 0.045% | 0.24% | ||
Частота появления первых букв слов или имен помогает предварительно выделить место в физических файлах и индексах.[16] Учитывая 26шкаф ящики, а не назначение одного ящика одной букве алфавита в соотношении 1: 1, часто бывает полезно использовать код с более равной частотой букв, назначая несколько низкочастотных букв одному и тому же ящику (часто один ящик маркируется VWXYZ), а также для разделения наиболее часто встречающихся начальных букв ('S', 'A' и 'C') на несколько ящиков (часто 6 ящиков Aa-An, Ao-Az, Ca-Cj, Ck-Cz, Sa-Si, Sj-Sz). Та же система используется в некоторых многотомных произведениях, например, в некоторых энциклопедии. Номера резаков в некоторых библиотеках используется другое сопоставление имен с более равномерно частотным кодом.
Как общее распределение букв, так и распределение начальных букв примерно соответствуют Распространение Zipf и даже более точно соответствовать Распределение Йоля.[17]
Часто частотное распределение первой цифры в каждом элементе данных значительно отличается от общей частоты всех цифр в наборе числовых данных, см. Закон Бенфорда для подробностей.
Анализ Питер Норвиг по данным Google Книг определяется, среди прочего, частота первых букв английских слов.[18]
Относительная частота букв в других языках
Эта статья возможно содержит несоответствующие или неверно истолкованные цитаты это не проверять текст. (Июль 2014 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |
| Письмо | английский | Французский [19] | Немецкий [20] | испанский [21] | португальский [22] | эсперанто [23] | Итальянский [24] | турецкий [25] | Шведский [26] | Польский [27] | нидерландский язык [28] | Датский [29] | исландский [30] | Финский [31] | Чешский |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| а | 8.167% | 7.636% | 6.516% | 11.525% | 14.634% | 12.117% | 11.745% | 11.920% | 9.383% | 8.910% | 7.486% | 6.025% | 10.110% | 12.217% | 8.421% |
| б | 1.492% | 0.901% | 1.886% | 2.215% | 1.043% | 0.980% | 0.927% | 2.844% | 1.535% | 1.470% | 1.584% | 2.000% | 1.043% | 0.281% | 0.822% |
| c | 2.782% | 3.260% | 2.732% | 4.019% | 3.882% | 0.776% | 4.501% | 0.963% | 1.486% | 3.960% | 1.242% | 0.565% | 0 | 0.281% | 0.740% |
| d | 4.253% | 3.669% | 5.076% | 5.010% | 4.992% | 3.044% | 3.736% | 4.706% | 4.702% | 3.250% | 5.933% | 5.858% | 1.575% | 1.043% | 3.475% |
| е | 12.702% | 14.715% | 16.396% | 12.181% | 12.570% | 8.995% | 11.792% | 8.912% | 10.149% | 7.660% | 18.91% | 15.453% | 6.418% | 7.968% | 7.562% |
| ж | 2.228% | 1.066% | 1.656% | 0.692% | 1.023% | 1.037% | 1.153% | 0.461% | 2.027% | 0.300% | 0.805% | 2.406% | 3.013% | 0.194% | 0.084% |
| грамм | 2.015% | 0.866% | 3.009% | 1.768% | 1.303% | 1.171% | 1.644% | 1.253% | 2.862% | 1.420% | 3.403% | 4.077% | 4.241% | 0.392% | 0.092% |
| час | 6.094% | 0.737% | 4.577% | 0.703% | 0.781% | 0.384% | 0.636% | 1.212% | 2.090% | 1.080% | 2.380% | 1.621% | 1.871% | 1.851% | 1.356% |
| я | 6.966% | 7.529% | 6.550% | 6.247% | 6.186% | 10.012% | 10.143% | 8.600%* | 5.817% | 8.210% | 6.499% | 6.000% | 7.578% | 10.817% | 6.073% |
| j | 0.153% | 0.613% | 0.268% | 0.493% | 0.397% | 3.501% | 0.011% | 0.034% | 0.614% | 2.280% | 1.46% | 0.730% | 1.144% | 2.042% | 1.433% |
| k | 0.772% | 0.074% | 1.417% | 0.011% | 0.015% | 4.163% | 0.009% | 4.683% | 3.140% | 3.510% | 2.248% | 3.395% | 3.314% | 4.973% | 2.894% |
| л | 4.025% | 5.456% | 3.437% | 4.967% | 2.779% | 6.104% | 6.510% | 5.922% | 5.275% | 2.100% | 3.568% | 5.229% | 4.532% | 5.761% | 3.802% |
| м | 2.406% | 2.968% | 2.534% | 3.157% | 4.738% | 2.994% | 2.512% | 3.752% | 3.471% | 2.800% | 2.213% | 3.237% | 4.041% | 3.202% | 2.446% |
| п | 6.749% | 7.095% | 9.776% | 6.712% | 4.446% | 7.955% | 6.883% | 7.487% | 8.542% | 5.520% | 10.032% | 7.240% | 7.711% | 8.826% | 6.468% |
| о | 7.507% | 5.796% | 2.594% | 8.683% | 9.735% | 8.779% | 9.832% | 2.476% | 4.482% | 7.750% | 6.063% | 4.636% | 2.166% | 5.614% | 6.695% |
| п | 1.929% | 2.521% | 0.670% | 2.510% | 2.523% | 2.755% | 3.056% | 0.886% | 1.839% | 3.130% | 1.57% | 1.756% | 0.789% | 1.842% | 1.906% |
| q | 0.095% | 1.362% | 0.018% | 0.877% | 1.204% | 0 | 0.505% | 0 | 0.020% | 0.140% | 0.009% | 0.007% | 0 | 0.013% | 0.001% |
| р | 5.987% | 6.693% | 7.003% | 6.871% | 6.530% | 5.914% | 6.367% | 6.722% | 8.431% | 4.690% | 6.411% | 8.956% | 8.581% | 2.872% | 4.799% |
| s | 6.327% | 7.948% | 7.270% | 7.977% | 6.805% | 6.092% | 4.981% | 3.014% | 6.590% | 4.320% | 3.73% | 5.805% | 5.630% | 7.862% | 5.212% |
| т | 9.056% | 7.244% | 6.154% | 4.632% | 4.336% | 5.276% | 5.623% | 3.314% | 7.691% | 3.980% | 6.79% | 6.862% | 4.953% | 8.750% | 5.727% |
| ты | 2.758% | 6.311% | 4.166% | 2.927% | 3.639% | 3.183% | 3.011% | 3.235% | 1.919% | 2.500% | 1.99% | 1.979% | 4.562% | 5.008% | 2.160% |
| v | 0.978% | 1.838% | 0.846% | 1.138% | 1.575% | 1.904% | 2.097% | 0.959% | 2.415% | 0.040% | 2.85% | 2.332% | 2.437% | 2.250% | 5.344% |
| ш | 2.360% | 0.049% | 1.921% | 0.017% | 0.037% | 0 | 0.033% | 0 | 0.142% | 4.650% | 1.52% | 0.069% | 0 | 0.094% | 0.016% |
| Икс | 0.150% | 0.427% | 0.034% | 0.215% | 0.253% | 0 | 0.003% | 0 | 0.159% | 0.020% | 0.036% | 0.028% | 0.046% | 0.031% | 0.027% |
| у | 1.974% | 0.128% | 0.039% | 1.008% | 0.006% | 0 | 0.020% | 3.336% | 0.708% | 3.760% | 0.035% | 0.698% | 0.900% | 1.745% | 1.043% |
| z | 0.074% | 0.326% | 1.134% | 0.467% | 0.470% | 0.494% | 1.181% | 1.500% | 0.070% | 5.640% | 1.39% | 0.034% | 0 | 0.051% | 1.599% |
| à | ~0% | 0.486% | 0 | 0 | 0.072% | 0 | 0.635% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| â | ~0% | 0.051% | 0 | 0 | 0.562% | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| á | 0 | 0 | 0 | 0.502% | 0.118% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.799% | 0 | 0.867% |
| å | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.338% | 0 | 0 | 1.190% | 0 | 0.003% | 0 |
| ä | 0 | 0 | 0.578% | 0 | 0 | 0 | 0 | 0 | 1.797% | 0 | 0 | 0 | 0 | 3.577% | 0 |
| ã | 0 | 0 | 0 | 0 | 0.733% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ą | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.990% | 0 | 0 | 0 | 0 | 0 |
| æ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.872% | 0.867% | 0 | 0 |
| œ | 0 | 0.018% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ç | ~0% | 0.085% | 0 | 0 | 0.530% | 0 | 0 | 1.156% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ĉ | 0 | 0 | 0 | 0 | 0 | 0.657% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ć | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.400% | 0 | 0 | 0 | 0 | 0 |
| č | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.462% |
| ď | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.015% |
| ð | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4.393% | 0 | 0 |
| è | ~0% | 0.271% | 0 | 0 | 0 | 0 | 0.263% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| é | ~0% | 1.504% | 0 | 0.433% | 0.337% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.647% | 0 | 0.633% |
| ê | 0 | 0.218% | 0 | 0 | 0.450% | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ë | ~0% | 0.008% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ę | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.110% | 0 | 0 | 0 | 0 | 0 |
| ě | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.222% |
| грамм | 0 | 0 | 0 | 0 | 0 | 0.691% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| грамм | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.125% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| час | 0 | 0 | 0 | 0 | 0 | 0.022% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| я | 0 | 0.045% | 0 | 0 | 0 | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| я | 0 | 0 | 0 | 0 | 0 | 0 | (0.030%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| я | 0 | 0 | 0 | 0.725% | 0.132% | 0 | 0.030% | 0 | 0 | 0 | 0 | 0 | 1.570% | 0 | 1.643% |
| я | ~0% | 0.005% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| я | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5.114%* | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ĵ | 0 | 0 | 0 | 0 | 0 | 0.055% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ł | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.820% | 0 | 0 | 0 | 0 | 0 |
| ñ | ~0% | 0 | 0 | 0.311% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ń | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.200% | 0 | 0 | 0 | 0 | 0 |
| ň | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.007% |
| ò | 0 | 0 | 0 | 0 | 0 | 0 | 0.002% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ö | ~0% | 0 | 0.443% | 0 | 0 | 0 | 0 | 0.777% | 1.305% | 0 | 0 | 0 | 0.777% | 0.444% | 0 |
| ô | ~0% | 0.023% | 0 | 0 | 0.635% | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ó | 0 | 0 | 0 | 0.827% | 0.296% | 0 | ~0% | 0 | 0 | 0.850% | 0 | 0 | 0.994% | 0 | 0.024% |
| х | 0 | 0 | 0 | 0 | 0.040% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ø | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.939% | 0 | 0 | 0 |
| р | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.380% |
| ŝ | 0 | 0 | 0 | 0 | 0 | 0.385% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ş | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.780% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ś | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.660% | 0 | 0 | 0 | 0 | 0 |
| š | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.688% |
| SS | 0 | 0 | 0.307% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ť | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.006% |
| þ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.455% | 0 | 0 |
| ù | 0 | 0.058% | 0 | 0 | 0 | 0 | (0.166%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ú | 0 | 0 | 0 | 0.168% | 0.207% | 0 | 0.166% | 0 | 0 | 0 | 0 | 0 | 0.613% | 0 | 0.045% |
| û | ~0% | 0.060% | 0 | 0 | 0 | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ŭ | 0 | 0 | 0 | 0 | 0 | 0.520% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ü | ~0% | 0 | 0.995% | 0.012% | 0.026% | 0 | 0 | 1.854% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ů | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.204% |
| ý | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.228% | 0 | 0.995% |
| ź | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.060% | 0 | 0 | 0 | 0 | 0 |
| ż | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.830% | 0 | 0 | 0 | 0 | 0 |
| ž | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.721% |
*Видеть Пунктирная и без точек я.
На рисунке ниже показано частотное распределение 26 наиболее распространенных латинских букв в некоторых языках. Все эти языки используют одинаковый алфавит из 25+ символов.
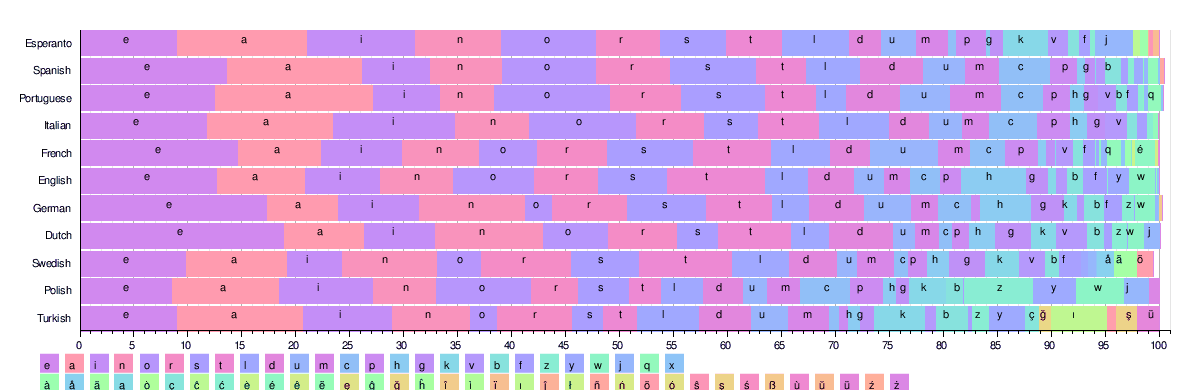
На основании этих таблицЭтаоин Шрдлу '-эквивалентные результаты для каждого языка следующие:
- Французский: esait nruol; (Индоевропейский: курсив; традиционно используется esartinulop, отчасти из-за простоты произношения.[32])
- Испанский: «eaosr nidlt»; (Индоевропейский: курсив)
- Португальский: 'aeosr idmnt' (индоевропейский: курсив)
- Итальянский: 'eaion lrtsc'; (Индоевропейский: курсив)
- Эсперанто: 'aieon lsrtk' (искусственный язык - лексика, на которую оказали влияние индоевропейские языки, романский, в основном германский)
- Немецкий: «enisr atdhu»; (Индоевропейский: германский)
- Шведский: «eanrt sildo»; (Индоевропейский: германский)
- Турецкий: 'aeinr lkdım'; (Тюркский)
- Голландский: «enati rodsl»; (Индоевропейский: германский)[28]
- Польский: «aioez nrwst»; (Индоевропейский: балто-славянский)
- Датский: 'ernta idslo'; (Индоевропейский: германский)
- Исландский: «arnie stulð»; (Индоевропейский: германский)
- Финский: «ainte slouk»; (Уральский: Финский)
- Чешский: 'aeoni tvsrl'; (Индоевропейский: балто-славянский)
Смотрите также
- Корпусная лингвистика
- RSTLNE (Колесо фортуны)
- Частота английских слов
- Частота арабских букв
- Раскладка клавиатуры Дворжака
Примечания
- ^ Американский код Морзе был разработан в 1830-х годах Альфред Вейл, основанный на частотах букв английского языка, для кодирования наиболее частых букв самыми короткими символами. Некоторая эффективность была потеряна в реформированной версии, используемой сейчас: Международной азбуке Морзе.
Цитаты
- ^ По, Эдгар Аллан. "Произведения Эдгара Аллана По в пяти томах". Проект Гутенберг.
- ^ Морено, Марша Линн (весна 2005 г.). «Частотный анализ в свете языковых инноваций» (PDF). Математика. Калифорнийский университет в Сан-Диего. Получено 19 февраля 2015.
- ^ Зим, Герберт Спенсер (1961). Коды и секретное письмо: авторизованное сокращение. Учебные книжные услуги. OCLC 317853773.
- ^ «Британская и американская орфография - Оксфордские словари». Оксфордские словари - английский. Получено 18 апреля 2018.
- ^ Ли, Вэньтянь; Мирамонтес, Педро (2011). «Фиттинг оценил распределение частотности писем на английском и испанском языках в выступлениях президентов США и Мексики». Журнал количественной лингвистики. 18 (4): 359. arXiv:1103.2950. Дои:10.1080/09296174.2011.608606. S2CID 1716455.
- ^ Гусейн-Заде, С. (1988). «Частота распространения букв русского языка». Пробл. Передачи Инф. 24 (4): 102–107.
- ^ Гамов, Георгий; Ycas, Мартинас (1955). «Статистическая корреляция состава белка и рибонуклеиновой кислоты». Proc. Natl. Акад. Наука. 41 (12): 1011–1019. Bibcode:1955ПНАС ... 41.1011Г. Дои:10.1073 / pnas.41.12.1011. ЧВК 528190. PMID 16589789.
- ^ Бауэр, Фридрих Л. (2006). Расшифрованные секреты: методы и принципы криптологии. п. 57. ISBN 9783540481218 - через Google Книги.
- ^ Гебель, Грег (2009). The Rise Of Field Ciphers: разные шифры в шахматную доску.
- ^ Райменанц, Дирк. «Одноразовый блокнот».
- ^ "Какая частота букв алфавита в английском?". Оксфордский словарь. Oxford University Press. Получено 29 декабря 2012.
- ^ Мичка, Павел. "Частота букв (английский)". Algoritmy.net.
- ^ «Таблица частот». Cornell.edu.
- ^ «Статистические распределения английского текста». data-compression.com. Архивировано из оригинал на 2017-09-18.
- ^ Ли, Э. Стюарт. «Очерки компьютерной безопасности» (PDF). Компьютерная лаборатория Кембриджского университета. п. 181.
- ^ Ольман, Герберт Марвин (1959). Частота букв предметного слова в приложениях к наложенному кодированию. Материалы Международной конференции по научной информации.
- ^ Панде, Гемлата; Дхами, Х.С. «Математическое моделирование появления букв и инициалов слов в текстах на языке хинди» (PDF). JTL. 16.
- ^ "Частота английских букв: пересмотр Майзнера или ETAOIN SRHLDCU". norvig.com. Получено 18 апреля 2018.
- ^ "Corpus de Thomas Tempé". Архивировано из оригинал 30 сентября 2007 г.. Получено 15 июн 2007.
- ^ Бойтельшпахер, Альбрехт (2005). Криптология (7-е изд.). Висбаден: Vieweg. п. 10. ISBN 3-8348-0014-7.
- ^ Пратт, Флетчер (1942). Секретно и срочно: история кодов и шифров. Garden City, NY: Blue Ribbon Books. С. 254–5. OCLC 795065.
- ^ "Frequência da ocorrência de letras no Português". Архивировано из оригинал 3 августа 2009 г.. Получено 16 июн 2009.
- ^ "La Oftecoj de la Esperantaj Literoj". Получено 14 сентября 2007.
- ^ Сингх, Саймон; Галли, Стефано (1999). Codici e Segreti (на итальянском). Милан: Риццоли. ISBN 978-8-817-86213-4. OCLC 535461359.
- ^ Серенгил, Сефик Илькин; Акин, Мурат (20–22 февраля 2011 г.). Атака на турецкие тексты, зашифрованные гомофоническим шифром (PDF). Труды 10-й Международной конференции WSEAS по электронике, аппаратному обеспечению, беспроводной и оптической связи. Кембридж, Великобритания. С. 123–126.
- ^ «Практическая криптография». Получено 30 октября 2013.
- ^ https://sjp.pwn.pl/poradnia/haslo/frekwencja-liter-w-polskich-tekstach;7072.html
- ^ а б "Letterfrequenties". Genootschap OnzeTaal. Получено 17 мая 2009.
- ^ "Частоты датских букв". Практическая криптография. Получено 24 октября 2013.
- ^ "Частоты исландских букв". Практическая криптография. Получено 24 октября 2013.
- ^ "Частоты финских букв". Практическая криптография. Получено 24 октября 2013.
- ^ Перек, Жорж; Алфавиты; Éditions Galilée, 1976 г.
Некоторые полезные таблицы для частот одной буквы, биграммы, триграммы, тетраграммы и пентаграммы на основе 20 000 слов, которые учитывают комбинации длины слова и позиции буквы для слов длиной от 3 до 7 букв. Ссылки следующие:
- Майзнер, M.S .; Tresselt, M.E .; Волин, Б. (1965). «Таблицы подсчета частоты однобуквенных и диграмм для различных комбинаций длины слова и буквенного положения». Дополнения к психономическим монографиям. 1 (2): 13–32. OCLC 639975358.
- Майзнер, M.S .; Tresselt, M.E .; Волин, Б. (1965). «Таблицы частот триграмм для различных комбинаций длины слова и буквенного положения». Дополнения к психономическим монографиям. 1 (3): 33–78.
- Майзнер, M.S .; Tresselt, M.E .; Волин, Б. (1965). «Таблицы частотности тетраграммы для различных комбинаций длины слова и буквенного положения». Дополнения к психономическим монографиям. 1 (4): 79–143.
- Майзнер, M.S .; Tresselt, M.E .; Волин, Б. (1965). «Таблицы частот пентаграммы для различных комбинаций длины слова и буквенного положения». Дополнения к психономическим монографиям. 1 (5): 144–190.
внешняя ссылка
- Леванд, Роберт Эдвард. «Криптографическая математика». pages.central.edu. Архивировано из оригинал на 2007-04-02.
- «Некоторые примеры рейтинга частоты букв в некоторых распространенных языках». www.bckelk.ukfsn.org.
- «Визуализация тепловой карты JavaScript, показывающая частоту букв в текстах на разных раскладках клавиатуры». www.patrick-wied.at.
- Норвиг, Питер. «Обновленная версия работы Майзнера с использованием набора данных Google books Ngrams». norvig.com.