Ковариация и контравариантность (информатика) - Covariance and contravariance (computer science)
| Системы типов |
|---|
| Общие понятия |
| Основные категории |
|
| Второстепенные категории |
| Смотрите также |
Много язык программирования системы типов поддерживать подтип. Например, если тип Кот это подтип Животное, то выражение типа Кот должен быть заменяемым везде, где выражение типа Животное используется.
Дисперсия относится к тому, как подтипы между более сложными типами связаны с подтипами между их компонентами. Например, как следует список Котs относятся к списку Животноес? Или как функция, возвращающая Кот относятся к функции, которая возвращает Животное?
В зависимости от дисперсии конструктор типов отношение подтипов простых типов может быть сохранено, изменено или проигнорировано для соответствующих сложных типов. в OCaml язык программирования, например, «список котов» является подтипом «список животных», потому что конструктор типа списка ковариантный. Это означает, что отношение подтипов простых типов сохраняется для сложных типов.
С другой стороны, «функция от животного к строке» является подтипом «функция от кошки к строке», потому что конструктор типа функции контравариантный в типе параметра. Здесь отношение подтипов простых типов меняется на обратное для сложных типов.
Разработчик языка программирования будет учитывать отклонения при разработке правил набора для таких языковых функций, как массивы, наследование и общие типы данных. Если сделать конструкторы типов ковариантными или контравариантными вместо инвариантных, больше программ будут приниматься как хорошо типизированные. С другой стороны, программисты часто находят контравариантность неинтуитивной, и точное отслеживание дисперсии во избежание ошибок типа во время выполнения может привести к сложным правилам типизации.
Чтобы система типов оставалась простой и позволяла использовать полезные программы, язык может рассматривать конструктор типа как инвариантный, даже если было бы безопасно считать его вариантом, или обрабатывать его как ковариантный, даже если это может нарушить безопасность типов.
Формальное определение
В рамках система типов из язык программирования, правило ввода или конструктор типа:
- ковариантный если он сохраняет заказ типов (≤), который упорядочивает типы от более конкретных к более общим;
- контравариантный если он меняет этот порядок;
- двувариантный если оба из них применимы (т. е. оба
я<А>≤я<B>ия<B>≤я<А>в то же время);[1] - вариант если ковариантный, контравариантный или двувариантный;
- инвариантный или же невариантный если не вариант.
В статье рассматривается, как это применимо к некоторым конструкторам распространенных типов.
Примеры C #
Например, в C #, если Кот это подтип Животное, тогда:
IEnumerable<Кот>это подтипIEnumerable<Животное>. Подтип сохраняется, потому чтоIEnumerable<Т>является ковариантный наТ.Действие<Животное>это подтипДействие<Кот>. Подтип обратный, потому чтоДействие<Т>является контравариантный наТ.- Ни один
IList<Кот>ниIList<Животное>является подтипом другого, потому чтоIList<Т>является инвариантный наТ.
Дисперсия универсального интерфейса C # объявляется путем размещения из (ковариантный) или в (контравариантный) атрибут (ноль или более) параметров его типа. Для каждого параметра типа, помеченного таким образом, компилятор окончательно проверяет, и любое нарушение является фатальным, что такое использование является глобально согласованным. Вышеуказанные интерфейсы объявлены как IEnumerable<из Т>, Действие<в Т>, и IList<Т>. Типы с более чем одним параметром типа могут указывать разные варианты для каждого параметра типа. Например, тип делегата Func<в Т, из TResult> представляет функцию с контравариантный входной параметр типа Т и ковариантный возвращаемое значение типа TResult.[2]
В правила ввода для дисперсии интерфейса обеспечить безопасность типов. Например, Действие<Т> представляет собой первоклассную функцию, ожидающую аргумента типа Т, и функцию, которая может обрабатывать любые типы животных, всегда можно использовать вместо функции, которая может обрабатывать только кошек.
Массивы
Типы данных (источники) только для чтения могут быть ковариантными; типы данных только для записи (приемники) могут быть контравариантными. Изменяемые типы данных, которые действуют как источники и приемники, должны быть инвариантными. Чтобы проиллюстрировать это общее явление, рассмотрим тип массива. Для типа Животное мы можем сделать тип Животное[], который представляет собой «массив животных». Для целей этого примера этот массив поддерживает как чтение, так и запись элементов.
У нас есть возможность рассматривать это как:
- ковариантный: a
Кот[]являетсяЖивотное[]; - контравариант:
Животное[]этоКот[]; - инвариант:
Животное[]это неКот[]иКот[]не являетсяЖивотное[].
Если мы хотим избежать ошибок типа, тогда безопасен только третий вариант. Понятно, что не каждый Животное[] можно рассматривать как если бы это был Кот[], поскольку клиент, читающий из массива, будет ожидать Кот, но Животное[] может содержать, например, а Собака. Так что контравариантное правило небезопасно.
И наоборот, a Кот[] нельзя рассматривать как Животное[]. Всегда должна быть возможность поставить Собака в Животное[]. С ковариантными массивами это не может быть гарантированно безопасно, поскольку резервное хранилище может фактически быть массивом кошек. Так что ковариантное правило также небезопасно - конструктор массива должен быть инвариантный. Обратите внимание, что это проблема только для изменяемых массивов; ковариантное правило безопасно для неизменяемых массивов (только для чтения).
С C # вы можете обойти это, используя динамическое ключевое слово над массивом / коллекцией / дженериками с утка печатать, intellisense таким образом теряется, но работает.
Ковариантные массивы в Java и C #
Ранние версии Java и C # не включали дженерики, также называемые параметрический полиморфизм. В таких условиях создание инвариантных массивов исключает использование полезных полиморфных программ.
Например, рассмотрите возможность написания функции для перемешивания массива или функции, которая проверяет два массива на равенство, используя Объект.равно метод на элементах. Реализация не зависит от точного типа элемента, хранящегося в массиве, поэтому должна быть возможность написать одну функцию, которая работает со всеми типами массивов. Легко реализовать функции типа:
логический equalArrays(Объект[] а1, Объект[] а2);пустота shuffleArray(Объект[] а);Однако, если бы типы массивов рассматривались как инвариантные, эти функции можно было бы вызывать только для массива точно такого типа. Объект[]. Например, нельзя было перетасовать массив строк.
Таким образом, и Java, и C # обрабатывают типы массивов ковариантно. Например, в Java Нить[] это подтип Объект[], а в C # нить[] это подтип объект[].
Как обсуждалось выше, ковариантные массивы приводят к проблемам с записью в массив. Java и C # справляются с этим путем пометки каждого объекта массива типом при его создании. Каждый раз, когда значение сохраняется в массиве, среда выполнения проверяет, что тип времени выполнения значения равен типу времени выполнения массива. Если есть несоответствие, ArrayStoreException (Java) или ArrayTypeMismatchException (C #) выбрасывается:
// a - одноэлементный массив StringНить[] а = новый Нить[1];// b - это массив ObjectОбъект[] б = а;// Присваиваем целое число b. Это было бы возможно, если бы b действительно было// массив Object, но поскольку это действительно массив String,// мы получим исключение java.lang.ArrayStoreException.б[0] = 1;В приведенном выше примере можно читать из массива (б) безопасно. Это всего лишь попытка записывать к массиву, что может привести к неприятностям.
Одним из недостатков этого подхода является то, что он оставляет возможность ошибки времени выполнения, которую система более строгих типов могла бы обнаружить во время компиляции. Кроме того, это снижает производительность, поскольку каждая запись в массив требует дополнительной проверки во время выполнения.
С добавлением дженериков Java и C # теперь предлагают способы написания такого рода полиморфных функций, не полагаясь на ковариантность. Функции сравнения массивов и перемешивания могут иметь параметризованные типы
<Т> логический equalArrays(Т[] а1, Т[] а2);<Т> пустота shuffleArray(Т[] а);В качестве альтернативы, чтобы обеспечить доступ метода C # к коллекции только для чтения, можно использовать интерфейс IEnumerable<объект> вместо того, чтобы передавать ему массив объект[].
Типы функций
Языки с первоклассные функции имеют типы функций например «функция, ожидающая кота и возвращающая животное» (написано Кот -> Животное в OCaml синтаксис или Func<Кот,Животное> в C # синтаксис).
Эти языки также должны указывать, когда один тип функции является подтипом другого, то есть когда безопасно использовать функцию одного типа в контексте, который ожидает функцию другого типа. Заменить функцию безопасно ж для функции грамм если ж принимает аргумент более общего типа и возвращает более конкретный тип, чем грамм. Например, функции типа Животное -> Кот, Кот -> Кот, и Животное -> Животное можно использовать везде, где Кот -> Животное ожидалось. (Можно сравнить это с принцип устойчивости коммуникации: «будьте либеральны в том, что вы принимаете, и консервативны в том, что вы производите»). Общее правило:
если и .



С помощью обозначение правила вывода это же правило можно записать так:

Другими словами, конструктор типа → контравариантный по типу ввода и ковариантный по типу вывода. Это правило впервые было официально сформулировано Джон С. Рейнольдс,[3] и далее популяризируется в статье Лука Карделли.[4]
При работе с функции, которые принимают функции в качестве аргументов, это правило можно применять несколько раз. Например, дважды применяя правило, мы видим, что (A '→ B) → B ≤ (A → B) → B, если A'≤A. Другими словами, тип (A → B) → B - это ковариантный в позиции А. Для сложных типов может быть сложно мысленно проследить, почему конкретная специализация типа является или не является типобезопасной, но легко вычислить, какие позиции являются ко- и контравариантными: позиция является ковариантной, если она находится в левой части к нему относится четное количество стрелок.
Наследование в объектно-ориентированных языках
Когда подкласс отменяет метод в суперклассе, компилятор должен проверить, что метод переопределения имеет правильный тип. В то время как некоторые языки требуют, чтобы тип точно соответствовал типу в суперклассе (инвариантность), также типобезопасно разрешить заменяющему методу иметь «лучший» тип. По обычному правилу выделения подтипов для типов функций это означает, что метод переопределения должен возвращать более конкретный тип (ковариация типа возвращаемого значения) и принимать более общий аргумент (контравариантность типа параметра). В UML обозначения, возможности следующие:
- Дисперсия и переопределение метода: обзор

Подтип параметра / типа возвращаемого значения метода.
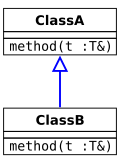
Инвариантность. Подпись метода переопределения не изменилась.
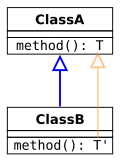
Ковариантный возвращаемый тип. Отношение подтипов находится в том же направлении, что и отношение между ClassA и ClassB.
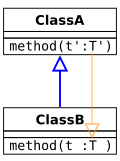
Контравариантный тип параметра. Отношение подтипов противоположно отношению между ClassA и ClassB.

Ковариантный тип параметра. Не безопасный тип.





В качестве конкретного примера предположим, что мы пишем класс для моделирования приют для животных. Мы предполагаем, что Кот является подклассом Животное, и что у нас есть базовый класс (с использованием синтаксиса Java)

учебный класс Приют для животных { Животное getAnimalForAdoption() { // ... } пустота putAnimal(Животное животное) { //... }}Теперь вопрос: если мы подклассифицируем Приют для животных, какие типы нам разрешено давать getAnimalForAdoption и putAnimal?
Тип возвращаемого значения ковариантного метода
На языке, который позволяет ковариантные возвращаемые типы, производный класс может переопределить getAnimalForAdoption метод для возврата более конкретного типа:
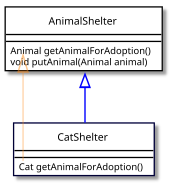
учебный класс CatShelter расширяет Приют для животных { Кот getAnimalForAdoption() { возвращаться новый Кот(); }}Среди основных ОО-языков Ява и C ++ поддерживают ковариантные возвращаемые типы, а C # не. Добавление ковариантного возвращаемого типа было одной из первых модификаций языка C ++, одобренных комитетом по стандартам в 1998 году.[5] Scala и D также поддерживают ковариантные возвращаемые типы.
Тип параметра контравариантного метода
Точно так же безопасно по типу разрешить переопределяющему методу принимать более общий аргумент, чем метод в базовом классе:

учебный класс CatShelter расширяет Приют для животных { пустота putAnimal(Объект животное) { // ... }}Не многие объектно-ориентированные языки действительно позволяют это. C ++ и Java интерпретировали бы это как несвязанный метод с перегружен имя.
Тем не мение, Sather поддерживает как ковариацию, так и контравариантность. Соглашение о вызове переопределенных методов ковариантно с из параметры и возвращаемые значения, и контравариантные с нормальными параметрами (с режимом в).
Тип параметра ковариантного метода
Пара основных языков, Эйфель и Дротик[6] позволяют параметрам замещающего метода иметь более конкретный тип, чем метод в суперклассе (ковариация типа параметра). Таким образом, следующий код Dart будет проверять тип с помощью putAnimal переопределение метода в базовом классе:

учебный класс CatShelter расширяет Приют для животных { пустота putAnimal(ковариантный Кот животное) { // ... }}Это небезопасно. Подняв CatShelter для Приют для животных, можно попробовать поместить собаку в приют для кошек. Это не соответствует CatShelter ограничения параметров и приведет к ошибке выполнения. Отсутствие безопасности типов (известное как «проблема перехвата» в сообществе Eiffel, где «кошка» или «CAT» - это измененная доступность или тип) было давней проблемой. За прошедшие годы были предложены различные комбинации глобального статического анализа, локального статического анализа и новых языковых функций, чтобы исправить это,[7][8] и они были реализованы в некоторых компиляторах Eiffel.
Несмотря на проблему безопасности типов, разработчики Eiffel считают ковариантные типы параметров решающими для моделирования требований реального мира.[8] Приют для кошек иллюстрирует обычное явление: это типа приют для животных, но есть дополнительные ограничения, и для моделирования этого кажется разумным использовать наследование и типы ограниченных параметров. Предлагая такое использование наследования, дизайнеры Eiffel отвергают Принцип подстановки Лискова, в котором говорится, что объекты подклассов всегда должны быть менее ограничены, чем объекты их суперкласса.
Еще один пример основного языка, допускающего ковариацию параметров метода, - это PHP в отношении конструкторов классов. В следующем примере принимается метод __construct (), несмотря на то, что параметр метода ковариантен параметру родительского метода. Если бы этот метод был любым, кроме __construct (), произошла бы ошибка:
интерфейс ЖивотноеИнтерфейс {}интерфейс DogInterface расширяет ЖивотноеИнтерфейс {}учебный класс Собака орудия DogInterface {}учебный класс Домашний питомец{ общественный функция __construct(ЖивотноеИнтерфейс $ животное) {}}учебный класс PetDog расширяет Домашний питомец{ общественный функция __construct(DogInterface $ собака) { родитель::__construct($ собака); }}Другой пример, когда ковариантные параметры кажутся полезными, - это так называемые бинарные методы, то есть методы, в которых параметр должен иметь тот же тип, что и объект, для которого вызывается метод. Примером может служить сравнить с метод: а.сравнить с(б) проверяет, есть ли а приходит до или после б в некотором порядке, но способ сравнения, скажем, двух рациональных чисел будет отличаться от способа сравнения двух строк. Другие распространенные примеры бинарных методов включают проверку на равенство, арифметические операции и операции над множеством, такие как подмножество и объединение.
В более старых версиях Java метод сравнения был указан как интерфейс Сопоставимый:
интерфейс Сопоставимый { int сравнить с(Объект о);}Недостатком этого является то, что для метода указан аргумент типа Объект. В типичной реализации этот аргумент сначала отбрасывается (выдает ошибку, если он не ожидаемого типа):
учебный класс Рациональное число орудия Сопоставимый { int числитель; int знаменатель; // ... общественный int сравнить с(Объект Другой) { Рациональное число otherNum = (Рациональное число)Другой; возвращаться Целое число.сравнивать(числитель * otherNum.знаменатель, otherNum.числитель * знаменатель); }}В языке с ковариантными параметрами аргумент сравнить с может быть напрямую задан желаемый тип Рациональное число, скрывая приведение типов. (Конечно, это все равно приведет к ошибке выполнения, если сравнить с затем был вызван, например, а Нить.)
Отсутствие необходимости в ковариантных типах параметров
Другие языковые особенности могут обеспечить очевидные преимущества ковариантных параметров при сохранении заменяемости Лискова.
На языке с дженерики (a.k.a. параметрический полиморфизм ) и ограниченная количественная оценка, предыдущие примеры могут быть написаны безопасным способом.[9] Вместо определения Приют для животных, мы определяем параметризованный класс Приют<Т>. (Одним из недостатков этого является то, что разработчик базового класса должен предвидеть, какие типы нужно будет специализировать в подклассах.)
учебный класс Приют<Т расширяет Животное> { Т getAnimalForAdoption() { // ... } пустота putAnimal(Т животное) { // ... }} учебный класс CatShelter расширяет Приют<Кот> { Кот getAnimalForAdoption() { // ... } пустота putAnimal(Кот животное) { // ... }}Точно так же в последних версиях Java Сопоставимый интерфейс параметризован, что позволяет опустить приведение вниз безопасным для типов способом:
учебный класс Рациональное число орудия Сопоставимый<Рациональное число> { int числитель; int знаменатель; // ... общественный int сравнить с(Рациональное число otherNum) { возвращаться Целое число.сравнивать(числитель * otherNum.знаменатель, otherNum.числитель * знаменатель); }}Еще одна языковая функция, которая может помочь: множественная отправка. Одна из причин, по которой двоичные методы неудобно писать, заключается в том, что при вызове типа а.сравнить с(б), выбрав правильную реализацию сравнить с действительно зависит от типа среды выполнения обоих а и б, но в обычном объектно-ориентированном языке только тип среды выполнения а учитывается. На языке с Общая объектная система Lisp (ЗАКРЫТЬ) -стиль множественная отправка, метод сравнения может быть записан как универсальная функция, в которой оба аргумента используются для выбора метода.
Джузеппе Кастанья[10] заметил, что в типизированном языке с множественной отправкой универсальная функция может иметь некоторые параметры, которые управляют отправкой, и некоторые "оставшиеся" параметры, которые этого не делают. Поскольку правило выбора метода выбирает наиболее конкретный применимый метод, если метод переопределяет другой метод, тогда у метода переопределения будут более конкретные типы для управляющих параметров. С другой стороны, для обеспечения безопасности типов язык по-прежнему должен требовать, чтобы оставшиеся параметры были как минимум такими же общими. Используя предыдущую терминологию, типы, используемые для выбора метода среды выполнения, являются ковариантными, тогда как типы, не используемые для выбора метода среды выполнения, являются контравариантными. Традиционные языки с единой диспетчеризацией, такие как Java, также подчиняются этому правилу: для выбора метода используется только один аргумент (объект-получатель, передаваемый методу в качестве скрытого аргумента это), да и тип это более специализирован внутри методов переопределения, чем в суперклассе.
Кастанья предлагает обрабатывать примеры, в которых ковариантные типы параметров превосходят (в частности, бинарные методы), с использованием множественной диспетчеризации; что естественно ковариантно. Однако большинство языков программирования не поддерживают множественную диспетчеризацию.
Резюме дисперсии и наследования
В следующей таблице приведены правила переопределения методов на языках, обсужденных выше.
| Тип параметра | Тип возврата | |
|---|---|---|
| C ++ (с 1998 г.), Ява (поскольку J2SE 5.0 ), D | Инвариантный | Ковариантный |
| C # | Инвариантный | Ковариантный (начиная с C # 9 - до инвариантного) |
| Scala, Sather | Контравариантный | Ковариантный |
| Эйфель | Ковариантный | Ковариантный |
Универсальные типы
В языках программирования, поддерживающих дженерики (a.k.a. параметрический полиморфизм ), программист может расширить систему типов с помощью новых конструкторов. Например, интерфейс C # вроде IList<Т> позволяет создавать новые типы, такие как IList<Животное> или же IList<Кот>. Тогда возникает вопрос, какой должна быть дисперсия этих конструкторов типов.
Есть два основных подхода. На языках с аннотации отклонений на сайте объявления (например., C # ), программист аннотирует определение универсального типа предполагаемой дисперсией его параметров типа. С аннотации вариантов использования сайта (например., Ява ), вместо этого программист аннотирует места, где создается универсальный тип.
Аннотации отклонений на объекте объявления
Самыми популярными языками с аннотациями отклонений на объекте объявления являются: C # и Котлин (используя ключевые слова из и в), и Scala и OCaml (используя ключевые слова + и -). C # допускает аннотации отклонений только для типов интерфейсов, в то время как Kotlin, Scala и OCaml допускают их как для типов интерфейсов, так и для конкретных типов данных.
Интерфейсы
В C # каждый параметр типа универсального интерфейса может быть помечен как ковариантный (из), контравариантный (в) или инвариантный (без аннотации). Например, мы можем определить интерфейс IEnumerator<Т> итераторов только для чтения и объявляют его ковариантным (выходящим) в параметре типа.
интерфейс IEnumerator<из Т>{ Т Текущий { получать; } bool MoveNext();}С этим заявлением IEnumerator будет рассматриваться как ковариантный по параметру типа, например IEnumerator<Кот> это подтип IEnumerator<Животное>.
Средство проверки типов обеспечивает, чтобы каждое объявление метода в интерфейсе упоминало только параметры типа в соответствии с в/из аннотации. То есть параметр, который был объявлен ковариантным, не должен встречаться в каких-либо контравариантных позициях (где позиция является контравариантной, если она встречается при нечетном количестве конструкторов контравариантного типа). Точное правило[11][12] заключается в том, что возвращаемые типы всех методов в интерфейсе должны быть действительный ковариантно и все типы параметров метода должны быть действительно контравариантно, куда действительный С-лы определяется следующим образом:
- Неуниверсальные типы (классы, структуры, перечисления и т. Д.) Действительны как ко-, так и контравариантно.
- Параметр типа
Тдействует ковариантно, если он не был отмеченв, и действует контравариантно, если он не был отмечениз. - Тип массива
А[]действительно S-ly, еслиАявляется. (Это потому, что в C # есть ковариантные массивы.) - Общий тип
грамм<A1, A2, ..., An>действительно С-лы, если для каждого параметраАй,- Ai действительно S-ly, а яth параметр для
граммобъявлен ковариантным, или - Ai действителен (не S) -y, а яth параметр для
граммобъявлен контравариантным, или - Ai действителен как ковариантно, так и контравариантно, и яth параметр для
граммобъявлен инвариантным.
- Ai действительно S-ly, а яth параметр для
В качестве примера применения этих правил рассмотрим IList<Т> интерфейс.
интерфейс IList<Т>{ пустота Вставлять(int индекс, Т элемент); IEnumerator<Т> GetEnumerator();}Тип параметра Т из Вставлять должен быть действительным контравариантно, т.е. параметр типа Т не должен быть помечен из. Аналогично тип результата IEnumerator<Т> из GetEnumerator должно быть ковариантно действительным, т.е. (поскольку IEnumerator ковариантный интерфейс) тип Т должен быть действительным ковариантно, т.е. параметр типа Т не должен быть помечен в. Это показывает, что интерфейс IList не может быть помечен как ко- или контравариантный.
В общем случае общей структуры данных, такой как IList, эти ограничения означают, что из параметр может использоваться только для методов, извлекающих данные из структуры, а параметр в Параметр может использоваться только для методов, помещающих данные в структуру, отсюда и выбор ключевых слов.
Данные
В C # разрешены аннотации к параметрам интерфейсов, но не к параметрам классов. Поскольку поля в классах C # всегда изменяемы, вариантно параметризованные классы в C # не очень полезны. Но языки, которые подчеркивают неизменность данных, могут хорошо использовать ковариантные типы данных. Например, во всех Scala, Котлин и OCaml неизменяемый тип списка ковариантен: Список[Кот] это подтип Список[Животное].
Правила Scala для проверки аннотаций отклонений по сути такие же, как в C #. Однако есть некоторые идиомы, которые применимы, в частности, к неизменяемым структурам данных. Они проиллюстрированы следующим (выдержкой из) определением Список[А] учебный класс.
запечатанный Абстрактные учебный класс Список[+ А] расширяет AbstractSeq[А] { def голова: А def хвост: Список[А] / ** Добавляет элемент в начало этого списка. * / def ::[B >: А] (Икс: B): Список[B] = новый Scala.коллекция.неизменный.::(Икс, это) /** ... */}Во-первых, члены класса с вариантным типом должны быть неизменяемыми. Здесь, голова имеет тип А, который был объявлен ковариантным (+), и действительно голова был объявлен как метод (def). Попытка объявить его как изменяемое поле (вар) будет отклонен как ошибка типа.
Во-вторых, даже если структура данных неизменна, у нее часто будут методы, в которых тип параметра встречается контравариантно. Например, рассмотрим метод :: который добавляет элемент в начало списка. (Реализация работает путем создания нового объекта с одноименным названием учебный класс ::, класс непустых списков.) Наиболее очевидным типом для него будет
def :: (Икс: А): Список[А]Однако это будет ошибкой типа, потому что ковариантный параметр А появляется в контравариантной позиции (как параметр функции). Но есть хитрость, чтобы обойти эту проблему. Мы даем :: более общий тип, позволяющий добавлять элемент любого типа B так долго как B это супертип А. Обратите внимание, что это зависит от Список ковариантно, поскольку это имеет тип Список[А] и мы относимся к нему как к имеющему тип Список[B]. На первый взгляд может быть неочевидно, что обобщенный тип является правильным, но если программист начинает с объявления более простого типа, ошибки типа укажут на то место, которое необходимо обобщить.
Вывод дисперсии
Можно разработать систему типов, в которой компилятор автоматически выводит аннотации наилучшей возможной дисперсии для всех параметров типа данных.[13] Однако анализ может быть сложным по нескольким причинам. Во-первых, анализ нелокален, поскольку дисперсия интерфейса я зависит от дисперсии всех интерфейсов, которые я упоминания. Во-вторых, чтобы получить уникальные лучшие решения, система типов должна позволять двувариантный параметры (одновременно ко- и контравариантные). И, наконец, изменение параметров типа, вероятно, должно быть преднамеренным выбором разработчика интерфейса, а не чем-то просто случаем.
Поэтому[14] большинство языков делают очень небольшой вывод о дисперсии. C # и Scala вообще не выводят никаких аннотаций дисперсии. OCaml может сделать вывод о дисперсии параметризованных конкретных типов данных, но программист должен явно указать дисперсию абстрактных типов (интерфейсов).
Например, рассмотрим тип данных OCaml Т который завершает функцию
тип ('а, 'б) т = Т из ('а -> 'б)Компилятор автоматически сделает вывод, что Т контравариантна по первому параметру и ковариантна по второму. Программист также может предоставить явные аннотации, которые компилятор проверит. Таким образом, следующее объявление эквивалентно предыдущему:
тип (-'а, +'б) т = Т из ('а -> 'б)Явные аннотации в OCaml становятся полезными при указании интерфейсов. Например, интерфейс стандартной библиотеки карта.S для ассоциативных таблиц включить аннотацию о том, что конструктор типа карты является ковариантным по типу результата.
модуль тип S = сиг тип ключ тип (+'а) т вал пустой: 'а т вал мем: ключ -> 'а т -> bool ... конецЭто гарантирует, что, например, Кот IntMap.т это подтип животное IntMap.т.
Аннотации вариативности сайта (подстановочные знаки)
Одним из недостатков подхода на основе объявления является то, что многие типы интерфейсов должны быть инвариантными. Например, мы видели выше, что IList должен быть инвариантным, потому что он содержит оба Вставлять и GetEnumerator. Чтобы выявить большую вариативность, разработчик API может предоставить дополнительные интерфейсы, которые предоставляют подмножества доступных методов (например, «список только для вставки», который предоставляет только Вставлять). Однако это быстро становится громоздким.
Вариант использования сайта означает, что желаемое отклонение указано с пометкой на конкретном сайте в коде, где будет использоваться тип. Это дает пользователям класса больше возможностей для создания подтипов, не требуя, чтобы разработчик класса определял несколько интерфейсов с различной дисперсией. Вместо этого в момент создания экземпляра универсального типа для фактического параметризованного типа программист может указать, что будет использоваться только подмножество его методов. Фактически, каждое определение универсального класса также предоставляет интерфейсы для ковариантных и контравариантных части этого класса.
Java предоставляет аннотации вариативности сайта через подстановочные знаки, ограниченная форма ограниченный экзистенциальные типы. Параметризованный тип может быть создан с помощью подстановочного знака ? вместе с верхней или нижней границей, например Список<? расширяет Животное> или же Список<? супер Животное>. Неограниченный подстановочный знак, например Список<?> эквивалентно Список<? расширяет Объект>. Такой тип представляет Список<Икс> для какого-то неизвестного типа Икс что удовлетворяет оценке. Например, если л имеет тип Список<? расширяет Животное>, тогда средство проверки типов примет
Животное а = л.получать(3);потому что тип Икс известен как подтип Животное, но
л.Добавить(новый Животное());будет отклонен как ошибка типа, поскольку Животное не обязательно Икс. В общем, учитывая некоторый интерфейс я<Т>, ссылка на я<? расширяет Т> запрещает использование методов из интерфейса, где Т встречается контравариантно в типе метода. Наоборот, если л имел тип Список<? супер Животное> можно было позвонить л.Добавить но нет л.получать.

В то время как параметризованные типы без подстановочных знаков в Java являются инвариантными (например, нет отношения подтипов между Список<Кот> и Список<Животное>) типы подстановочных знаков можно сделать более конкретными, указав более жесткую границу. Например, Список<? расширяет Кот> это подтип Список<? расширяет Животное>. Это показывает, что типы подстановочных знаков ковариантны по своим верхним оценкам (а также контравариантны по своим нижним оценкам). Всего, учитывая тип подстановочного знака, например C<? расширяет Т>, есть три способа сформировать подтип: путем специализации класса C, указав более жесткую границу Т, или заменив подстановочный знак ? с определенным типом (см. рисунок).
Применяя две из трех вышеперечисленных форм подтипов, становится возможным, например, передать аргумент типа Список<Кот> к методу, ожидающему Список<? расширяет Животное>. Это своего рода выразительность, которая является результатом ковариантных типов интерфейса. Тип Список<? расширяет Животное> действует как тип интерфейса, содержащий только ковариантные методы Список<Т>, но исполнитель Список<Т> не нужно было определять его заранее.
В общем случае общей структуры данных IList, ковариантные параметры используются для методов, извлекающих данные из структуры, а контравариантные параметры - для методов, помещающих данные в структуру. Мнемоника для Producer Extends, Consumer Super (PECS) из книги Эффективная Java к Джошуа Блох дает простой способ запомнить, когда использовать ковариацию и контравариантность.
Подстановочные знаки являются гибкими, но у них есть недостаток. Хотя вариативность на сайте означает, что разработчикам API не нужно учитывать вариации параметров типа и интерфейсов, вместо этого они должны использовать более сложные сигнатуры методов. Типичный пример включает Сопоставимый интерфейс. Предположим, мы хотим написать функцию, которая находит самый большой элемент в коллекции. Элементы должны реализовать сравнить с метод, поэтому первая попытка может быть
<Т расширяет Сопоставимый<Т>> Т Максимум(Коллекция<Т> колл);Однако этот тип не является достаточно общим - можно найти максимум Коллекция<Календарь>, но не Коллекция<Григорианский календарь>. Проблема в том, что Григорианский календарь не реализует Сопоставимый<Григорианский календарь>, но вместо этого (лучший) интерфейс Сопоставимый<Календарь>. В Java, в отличие от C #, Сопоставимый<Календарь> не считается подтипом Сопоставимый<Григорианский календарь>. Вместо типа Максимум необходимо изменить:
<Т расширяет Сопоставимый<? супер Т>> Т Максимум(Коллекция<Т> колл);Ограниченный подстановочный знак ? супер Т передает информацию, которая Максимум вызывает только контравариантные методы из Сопоставимый интерфейс. Этот конкретный пример расстраивает, потому что все методы в Сопоставимый контравариантны, так что условие тривиально выполняется. Система объявлений на сайте могла бы обработать этот пример с меньшим беспорядком, аннотируя только определение Сопоставимый.
Сравнение аннотаций сайта объявления и использования сайта
Аннотации вариантов использования сайта обеспечивают дополнительную гибкость, позволяя большему количеству программ выполнять проверку типа. Однако их критиковали за сложность, которую они добавляют к языку, что приводит к сложным сигнатурам типов и сообщениям об ошибках.
Один из способов оценить, полезна ли дополнительная гибкость, - это посмотреть, используется ли она в существующих программах. Обзор большого набора библиотек Java[13] обнаружил, что 39% аннотаций с подстановочными знаками можно было напрямую заменить аннотациями сайта объявления. Таким образом, оставшийся 61% указывает на те места, где Java извлекает выгоду из наличия системы использования сайта.
На языке сайта объявлений библиотеки должны либо предоставлять меньше вариантов, либо определять больше интерфейсов. Например, библиотека Scala Collections определяет три отдельных интерфейса для классов, использующих ковариацию: ковариантный базовый интерфейс, содержащий общие методы, инвариантная изменяемая версия, которая добавляет методы побочного эффекта, и ковариантная неизменяемая версия, которая может специализировать унаследованные реализации для использования структурных методов. обмен.[15] Этот дизайн хорошо работает с аннотациями сайтов объявлений, но большое количество интерфейсов дорого обходится клиентам библиотеки. И изменение интерфейса библиотеки может быть недопустимым вариантом - в частности, одной из целей при добавлении универсальных шаблонов в Java было поддержание обратной совместимости двоичных файлов.
С другой стороны, шаблоны Java сами по себе сложны. В презентации на конференции[16] Джошуа Блох раскритиковал их за то, что они слишком трудны для понимания и использования, заявив, что при добавлении поддержки закрытие "мы просто не можем позволить себе другого подстановочные знаки". В ранних версиях Scala использовались аннотации вариантов использования сайта, но программисты сочли их трудными для использования на практике, в то время как аннотации сайтов объявлений оказались очень полезными при разработке классов.[17] В более поздних версиях Scala были добавлены экзистенциальные типы и подстановочные знаки в стиле Java; однако, согласно Мартин Одерский, если бы не было необходимости во взаимодействии с Java, они, вероятно, не были бы включены.[18]
Росс Тейт утверждает[19] Эта часть сложности подстановочных знаков Java связана с решением кодировать вариативность сайта с использованием формы экзистенциальных типов. Оригинальные предложения[20][21] использовался специальный синтаксис для аннотаций отклонений, написание Список<+Животное> вместо более подробного Java Список<? расширяет Животное>.
Поскольку подстановочные знаки - это форма экзистенциальных типов, их можно использовать не только для дисперсии. Типа как Список<?> («список неизвестного типа»[22]) позволяет передавать объекты методам или сохранять в полях без точного указания их параметров типа. Это особенно ценно для таких классов, как Учебный класс где в большинстве методов не упоминается параметр типа.
Тем не мение, вывод типа для экзистенциальных типов - сложная проблема. Для разработчика компилятора подстановочные знаки Java вызывают проблемы с завершением проверки типов, выводом аргументов типа и неоднозначными программами.[23] В общем неразрешимый хорошо ли типизирована программа Java, использующая дженерики,[24] поэтому любой программе проверки типов придется зайти в бесконечный цикл или тайм-аут для некоторых программ. Для программиста это приводит к сообщениям об ошибках сложного типа. Тип Java проверяет типы подстановочных знаков, заменяя подстановочные знаки переменными нового типа (так называемые преобразование захвата). Это может затруднить чтение сообщений об ошибках, поскольку они относятся к переменным типа, которые программист не записывал напрямую. Например, при попытке добавить Кот к Список<? расширяет Животное> выдаст ошибку вроде
метод List.add (захват # 1) неприменим (фактический аргумент Cat не может быть преобразован в захват # 1 с помощью преобразования вызова метода), где захват # 1 является новой переменной типа: захват # 1 расширяет Animal из захвата? расширяет Animal
Поскольку могут быть полезны и аннотации сайта объявления, и места использования, некоторые системы типов предоставляют и то, и другое.[13][19]
Происхождение термина ковариация
Эти термины происходят из понятия ковариантные и контравариантные функторы в теория категорий. Рассмотрим категорию чьи объекты являются типами и чьи морфизмы представляют отношение подтипов ≤. (Это пример того, как любой частично упорядоченный набор можно рассматривать как категорию.) Тогда, например, конструктор типа функции принимает два типа п и р и создает новый тип п → р; поэтому он принимает объекты в к объектам в . По правилу выделения подтипов для типов функций эта операция меняет значение ≤ для первого параметра и сохраняет его для второго, так что это контравариантный функтор для первого параметра и ковариантный функтор для второго.


Смотрите также
Рекомендации
- ^ Это происходит только в патологическом случае. Например,
введите 'a t = int: любой тип можно использовать для'аи результат по-прежнемуint - ^ Func
- ^ Джон С. Рейнольдс (1981). Суть Алгола. Симпозиум по алгоритмическим языкам. Северная Голландия.
- ^ Лука Карделли (1984). Семантика множественного наследования (PDF). Семантика типов данных (Международный симпозиум Sophia-Antipolis, Франция, 27-29 июня 1984 г.). Конспект лекций по информатике. 173. Springer. Дои:10.1007/3-540-13346-1_2.(Более длинная версия в Information and Computing, 76 (2/3): 138-164, февраль 1988 г.)
- ^ Эллисон, Чак. "Что нового в стандартном C ++?".
- ^ «Устранение проблем общего типа». Язык программирования дротиков.
- ^ Бертран Мейер (октябрь 1995 г.). «Статический набор» (PDF). OOPSLA 95 (объектно-ориентированное программирование, системы, языки и приложения), Атланта, 1995 г..
- ^ а б Ховард, Марк; Безо, Эрик; Мейер, Бертран; Колне, Доминик; Стапф, Эммануэль; Арноут, Карин; Келлер, Маркус (апрель 2003 г.). «Типобезопасная ковариация: компетентные компиляторы могут уловить все возражения» (PDF). Получено 23 мая 2013.
- ^ Франц Вебер (1992). «Получение эквивалента правильности класса и правильности системы - как добиться правильной ковариации». TOOLS 8 (8-я конференция по технологии объектно-ориентированных языков и систем), Дортмунд, 1992 г.. CiteSeerX 10.1.1.52.7872.
- ^ Джузеппе Кастанья, Ковариация и контравариантность: конфликт без причины, Транзакции ACM по языкам и системам программирования, Том 17, выпуск 3, май 1995 г., страницы 431-447.
- ^ Эрик Липперт (3 декабря 2009 г.). «Точные правила допустимости отклонений». Получено 16 августа 2016.
- ^ Раздел II.9.7 в Международный стандарт ECMA ECMA-335 Common Language Infrastructure (CLI), 6-е издание (июнь 2012 г.); доступно онлайн
- ^ а б c Джон Алтидор; Хуан Шань Шань; Яннис Смарагдакис (2011). «Укрощение шаблонов: сочетание вариативности определения и использования сайта» (PDF). Материалы 32-й конференции ACM SIGPLAN по проектированию и реализации языков программирования (PLDI'11). Архивировано из оригинал (PDF) на 2012-01-06.
- ^ Эрик Липперт (29 октября 2007 г.). «Ковариация и контравариантность в C #, часть седьмая: зачем нам вообще нужен синтаксис?». Получено 16 августа 2016.
- ^ Марин Одерский; Лекс Спун (7 сентября 2010 г.). «API коллекций Scala 2.8». Получено 16 августа 2016.
- ^ Джошуа Блох (ноябрь 2007 г.). "Споры о закрытии [видео]". Презентация на Javapolis'07. Архивировано из оригинал на 2014-02-02. Дата обращения: май 2013 г.. Проверить значения даты в:
| accessdate =(помощь)CS1 maint: location (связь) - ^ Мартин Одерский; Маттиас Зенгер (2005). «Масштабируемые абстракции компонентов» (PDF). Материалы 20-й ежегодной конференции ACM SIGPLAN по объектно-ориентированному программированию, системам, языкам и приложениям (OOPSLA '05).
- ^ Билл Веннерс и Фрэнк Соммерс (18 мая 2009 г.). «Назначение системы типов Scala: беседа с Мартином Одерски, часть III». Получено 16 августа 2016.
- ^ а б Росс Тейт (2013). «Различия между сайтами». FOOL '13: Неформальные материалы 20-го Международного семинара по основам объектно-ориентированных языков.
- ^ Ацуши Игараси; Мирко Вироли (2002). «О подтипах на основе дисперсии для параметрических типов» (PDF). Труды 16-й Европейской конференции по объектно-ориентированному программированию (ECOOP '02). Архивировано из оригинал (PDF) на 22 июня 2006 г.
- ^ Крестен Краб Торуп; Мадс Торгерсен (1999). «Унификация универсальности: сочетание преимуществ виртуальных типов и параметризованных классов» (PDF). Объектно-ориентированное программирование (ECOOP '99). Архивировано из оригинал (PDF) на 2015-09-23. Получено 2013-10-06.
- ^ «Учебные пособия по Java ™, обобщенные шаблоны (обновленные), неограниченные подстановочные знаки». Получено 17 июля, 2020.
- ^ Тейт, Росс; Люнг, Алан; Лернер, Сорин (2011). «Укрощение подстановочных знаков в системе типов Java». Материалы 32-й конференции ACM SIGPLAN по проектированию и реализации языков программирования (PLDI '11).
- ^ Раду Григоре (2017). «Дженерики Java завершены по Тьюрингу». Материалы 44-го симпозиума ACM SIGPLAN по принципам языков программирования (POPL'17). arXiv:1605.05274. Bibcode:2016arXiv160505274G.
внешняя ссылка
- Сказочные приключения в кодировании: Серия статей о проблемах реализации, связанных с ко / контравариантностью в C #.
- Contra Vs Co Variance (обратите внимание, что эта статья не обновляется о C ++)
- Замыкания для языка программирования Java 7 (v0.5)
- Теория ковариации и контравариантности в C # 4